Using CFFI for embedding
Introduction
CFFI has been a great success so far to call C libraries in your Python programs, in a way that is both simple and that works across CPython 2.x and 3.x and PyPy.
This post assumes that you know what CFFI is and how to use it in API mode (ffi.cdef(), ffi.set_source(), ffi.compile()). A quick overview can be found in this paragraph.
The major news of CFFI 1.4, released last december, was that you can now declare C functions with extern "Python" in the cdef(). These magic keywords make the function callable from C (where it is defined automatically), but calling it will call some Python code (which you attach with the @ffi.def_extern() decorator). This is useful because it gives a more straightforward, faster and libffi-independent way to write callbacks. For more details, see the documentation.
You are, in effect, declaring a static family of C functions which call Python code. The idea is to take pointers to them, and pass them around to other C functions, as callbacks. However, the idea of a set of C functions which call Python code opens another path: embedding Python code inside non-Python programs.
Embedding
Embedding is traditionally done using the CPython C API: from C code, you call Py_Initialize() and then some other functions like PyRun_SimpleString(). In the simple cases it is, indeed, simple enough; but it can become a complicated story if you throw in supporting application-dependent object types; and a messy story if you add correctly running on multiple threads, for example.
Moreover, this approach is specific to CPython (2.x or 3.x). It does not work at all on PyPy, which has its own very different, minimal embedding API.
The new-and-coming thing about CFFI 1.5, meant as replacement of the above solutions, is direct embedding support---with no fixed API at all. The idea is to write some Python script with a cdef() which declares a number of extern "Python" functions. When running the script, it creates the C source code and compiles it to a dynamically-linked library (.so on Linux). This is the same as in the regular API-mode usage. What is new is that these extern "Python" can now also be exported from the .so, in the C sense. You also give a bit of initialization-time Python code directly in the script, which will be compiled into the .so too.
This library can now be used directly from any C program (and it is still importable in Python). It exposes the C API of your choice, which you specified with the extern "Python" declarations. You can use it to make whatever custom API makes sense in your particular case. You can even directly make a "plug-in" for any program that supports them, just by exporting the API expected for such plugins.
Trying it out on CPython
This is still being finalized, but please try it out. You can see embedding.py directly online for a quick glance. Or see below the instructions on Linux with CPython 2.7 (CPython 3.x and non-Linux platforms are still a work in progress right now, but this should be quickly fixed):
-
get the branch static-callback-embedding of CFFI:
hg clone https://foss.heptapod.net/cffi/cffi hg up static-callback-embedding
-
make the _cffi_backend.so:
python setup_base.py build_ext -f -i
-
run embedding.py in the demo directory:
cd demo PYTHONPATH=.. python embedding.py
-
this produces _embedding_cffi.c. Run gcc to build it. On Linux:
gcc -shared -fPIC _embedding_cffi.c -o _embedding_cffi.so \ -lpython2.7 -I/usr/include/python2.7 -
try out the demo C program in embedding_test.c:
gcc embedding_test.c _embedding_cffi.so PYTHONPATH=.. LD_LIBRARY_PATH=. ./a.out
Note that if you get ImportError: cffi extension module '_embedding_cffi' has unknown version 0x2701, it means that the _cffi_backend module loaded is a pre-installed one instead of the more recent one in "..". Be sure to use PYTHONPATH=.. for now. (Some installations manage to be confused enough to load the system-wide cffi even if another version is in the PYTHONPATH. I think a virtualenv can be used to work around this issue.)
Try it out on PyPy
Very similar steps can be followed on PyPy, but it requires the cffi-static-callback-embedding branch of PyPy, which you must first translate from sources. The difference is then that you need to adapt the first gcc command line: replace -lpython2.7 with -lpypy-c and to fix the -I path (and possibly add a -L path).
More details
How it works, more precisely, is by automatically initializing CPython/PyPy the first time any of the extern "Python" functions is called from the C program. This is done using locks in case of multi-threading, so several threads can concurrently do this "first call". This should work even if two different threads call the first time a function from two different embedded CFFI extensions that happen to be linked with the same program. Explicit initialization is never needed.
The custom initialization-time Python code you put in ffi.embedding_init_code() is executed at that time. If this code starts to be big, you can move it to independent modules or packages. Then the initialization-time Python code only needs to import them. In that case, you have to carefully set up sys.path if the modules are not installed in the usual Python way.
If the Python code is big and full of dependencies, a better alternative would be to use virtualenv. How to do that is not fully fleshed out so far. You can certainly run the whole program with the environment variables set up by the virtualenv's activate script first. There are probably other solutions that involve using gcc's -Wl,-rpath=\$ORIGIN/ or -Wl,-rpath=/fixed/path/ options to load a specific libpython or libypypy-c library. If you try it out and it doesn't work the way you would like, please complain :-)
Another point: right now this does not support CPython's notion of multiple subinterpreters. The logic creates a single global Python interpreter, and runs everything in that context. Maybe a future version would have an explicit API to do that — or maybe it should be the job of a 3rd-party extension module to provide a Python interface over the notion of subinterpreters...
More generally, any feedback is appreciated.
Have fun,
Armin
Leysin Winter Sprint (20-27th February 2016)
The next PyPy sprint will be in Leysin, Switzerland, for the eleventh time. This is a fully public sprint: newcomers and topics other than those proposed below are welcome.
Goals and topics of the sprint
The details depend on who is here and ready to work. The list of topics is mostly the same as last year (did PyPy became a mature project with only long-term goals?):
- cpyext (CPython C API emulation layer): various speed and completeness topics
- cleaning up the optimization step in the JIT, change the register allocation done by the JIT's backend, or more improvements to the warm-up time
- finish vmprof - a statistical profiler for CPython and PyPy
- Py3k (Python 3.x support), NumPyPy (the numpy module)
- STM (Software Transaction Memory), notably: try to come up with benchmarks, and measure them carefully in order to test and improve the conflict reporting tools, and more generally to figure out how practical it is in large projects to avoid conflicts
- And as usual, the main side goal is to have fun in winter sports :-) We can take a day off for ski.
Exact times
I have booked the week from Saturday 20 to Saturday 27. It is fine to leave either the 27 or the 28, or even stay a few more days on either side. The plan is to work full days between the 21 and the 27. You are of course allowed to show up for a part of that time only, too.
Location & Accomodation
Leysin, Switzerland, "same place as before". Let me refresh your memory: both the sprint venue and the lodging will be in a pair of chalets built specifically for bed & breakfast: https://www.ermina.ch/. The place has a good ADSL Internet connection with wireless installed. You can also arrange your own lodging elsewhere (as long as you are in Leysin, you cannot be more than a 15 minutes walk away from the sprint venue).
Please confirm that you are coming so that we can adjust the reservations as appropriate.
The options of rooms are a bit more limited than on previous years because the place for bed-and-breakfast is shrinking: what is guaranteed is only one double-bed room and a bigger room with 5-6 individual beds (the latter at 50-60 CHF per night, breakfast included). If there are more people that would prefer a single room, please contact me and we'll see what choices you have. There are a choice of hotels, many of them reasonably priced for Switzerland.
Please register by Mercurial:
https://bitbucket.org/pypy/extradoc/
https://foss.heptapod.net/pypy/extradoc/-/blob/branch/default/extradoc/sprintinfo/leysin-winter-2016
or on the pypy-dev mailing list if you do not yet have check-in rights:
https://mail.python.org/mailman/listinfo/pypy-dev
You need a Swiss-to-(insert country here) power adapter. There will be some Swiss-to-EU adapters around, and at least one EU-format power strip.
PyPy 4.0.1 released please update
PyPy 4.0.1
We have released PyPy 4.0.1, three weeks after PyPy 4.0.0. We have fixed a few critical bugs in the JIT compiled code, reported by users. We therefore encourage all users of PyPy to update to this version. There are a few minor enhancements in this version as well.
You can download the PyPy 4.0.1 release here:
We would like to thank our donors for the continued support of the PyPy project.
We would also like to thank our contributors and encourage new people to join the project. PyPy has many layers and we need help with all of them: PyPy and RPython documentation improvements, tweaking popular modules to run on pypy, or general help with making RPython’s JIT even better.
CFFI update
While not applicable only to PyPy, cffi is arguably our most significant contribution to the python ecosystem. PyPy 4.0.1 ships with cffi-1.3.1 with the improvements it brings.
What is PyPy?
PyPy is a very compliant Python interpreter, almost a drop-in replacement for CPython 2.7. It’s fast (pypy and cpython 2.7.x performance comparison) due to its integrated tracing JIT compiler.
We also welcome developers of other dynamic languages to see what RPython can do for them.
This release supports x86 machines on most common operating systems (Linux 32/64, Mac OS X 64, Windows 32, OpenBSD, freebsd), newer ARM hardware (ARMv6 or ARMv7, with VFPv3) running Linux, and the big- and little-endian variants of ppc64 running Linux.
Other Highlights (since 4.0.0 released three weeks ago)
-
Bug Fixes
- Fix a bug when unrolling double loops in JITted code
- Fix multiple memory leaks in the ssl module, one of which affected CPython as well (thanks to Alex Gaynor for pointing those out)
- Use pkg-config to find ssl headers on OS-X
- Issues reported with our previous release were resolved after reports from users on our issue tracker at https://foss.heptapod.net/pypy/pypy/-/issues or on IRC at #pypy
-
New features
- Internal cleanup of RPython class handling
- Support stackless and greenlets on PPC machines
- Improve debug logging in subprocesses: use PYPYLOG=jit:log.%d for example to have all subprocesses write the JIT log to a file called ‘log.%d’, with ‘%d’ replaced with the subprocess’ PID.
- Support PyOS_double_to_string in our cpyext capi compatibility layer
-
Numpy
- Improve support for __array_interface__
- Propagate most NAN mantissas through float16-float32-float64 conversions
-
Performance improvements and refactorings
- Improvements in slicing byte arrays
- Improvements in enumerate()
- Silence some warnings while translating
Cheers
The PyPy Team
I'd love to upgrade and see if that makes my segfault go away, but the builds at https://launchpad.net/~pypy/+archive/ubuntu/ppa?field.series_filter=precise are two weeks old?
Hi Marius! How about directing such complains to the maintainer of the PPA instead of us? :-)
https://bitbucket.org/pypy/benchmarks , file runner.py. This file has various options; try this: ``python runner.py --changed /path/to/pypy``. This example would compare the speed on top of your system's python and on top of /path/to/pypy. Try also ``--fast`` if you're not patient enough.
Thanks Armin, that got me a result.json file - is there a tool to present the data in a more human-readable way?
The command itself prints a human-readable result at the end; you can ignore result.json.
PyPy 4.0.0 Released - A Jit with SIMD Vectorization and More
PyPy 4.0.0
We’re pleased and proud to unleash PyPy 4.0.0, a major update of the PyPy python 2.7.10 compatible interpreter with a Just In Time compiler. We have improved warmup time and memory overhead used for tracing, added vectorization for numpy and general loops where possible on x86 hardware (disabled by default), refactored rough edges in rpython, and increased functionality of numpy.You can download the PyPy 4.0.0 release here:
We would like to thank our donors for the continued support of the PyPy project.
We would also like to thank our contributors (7 new ones since PyPy 2.6.0) and encourage new people to join the project. PyPy has many layers and we need help with all of them: PyPy and RPython documentation improvements, tweaking popular modules to run on PyPy, or general help with making RPython’s JIT even better.
New Version Numbering
Vectorization
Availability of SIMD hardware is detected at run time, without needing to precompile various code paths into the executable.
The first version of the vectorization has been merged in this release, since it is so new it is off by default. To enable the vectorization in built-in JIT drivers (like numpy ufuncs), add –jit vec=1, to enable all implemented vectorization add –jit vec_all=1
Benchmarks and a summary of this work appear here
Internal Refactoring: Warmup Time Improvement and Reduced Memory Usage
Numpy
Our implementation of numpy continues to improve. ndarray and the numeric dtypes are very close to feature-complete; record, string and unicode dtypes are mostly supported. We have reimplemented numpy linalg, random and fft as cffi-1.0 modules that call out to the same underlying libraries that upstream numpy uses. Please try it out, especially using the new vectorization (via –jit vec=1 on the command line) and let us know what is missing for your code.
CFFI
While not applicable only to PyPy, cffi is arguably our most significant contribution to the python ecosystem. Armin Rigo continued improving it, and PyPy reaps the benefits of cffi-1.3: improved manangement of object lifetimes, __stdcall on Win32, ffi.memmove(), and percolate
const, restrict keywords from cdef to C code.What is PyPy?
PyPy is a very compliant Python interpreter, almost a drop-in replacement for CPython 2.7. It’s fast (pypy and cpython 2.7.x performance comparison) due to its integrated tracing JIT compiler.
We also welcome developers of other dynamic languages to see what RPython can do for them.
This release supports x86 machines on most common operating systems (Linux 32/64, Mac OS X 64, Windows 32, OpenBSD, freebsd), as well as newer ARM hardware (ARMv6 or ARMv7, with VFPv3) running Linux.
We also introduce support for the 64 bit PowerPC hardware, specifically Linux running the big- and little-endian variants of ppc64.
Other Highlights (since 2.6.1 release two months ago)
-
Bug Fixes
- Applied OPENBSD downstream fixes
- Fix a crash on non-linux when running more than 20 threads
- In cffi, ffi.new_handle() is more cpython compliant
- Accept unicode in functions inside the _curses cffi backend exactly like cpython
- Fix a segfault in itertools.islice()
- Use gcrootfinder=shadowstack by default, asmgcc on linux only
- Fix ndarray.copy() for upstream compatability when copying non-contiguous arrays
- Fix assumption that lltype.UniChar is unsigned
- Fix a subtle bug with stacklets on shadowstack
- Improve support for the cpython capi in cpyext (our capi compatibility layer). Fixing these issues inspired some thought about cpyext in general, stay tuned for more improvements
- When loading dynamic libraries, in case of a certain loading error, retry loading the library assuming it is actually a linker script, like on Arch and Gentoo
- Issues reported with our previous release were resolved after reports from users on our issue tracker at https://foss.heptapod.net/pypy/pypy/-/issues or on IRC at #pypy
-
New features:
- Add an optimization pass to vectorize loops using x86 SIMD intrinsics.
- Support __stdcall on Windows in CFFI
- Improve debug logging when using PYPYLOG=???
- Deal with platforms with no RAND_egd() in OpenSSL
-
Numpy:
- Add support for ndarray.ctypes
- Fast path for mixing numpy scalars and floats
- Add support for creating Fortran-ordered ndarrays
- Fix casting failures in linalg (by extending ufunc casting)
- Recognize and disallow (for now) pickling of ndarrays with objects embedded in them
-
Performance improvements and refactorings:
- Reuse hashed keys across dictionaries and sets
- Refactor JIT interals to improve warmup time by 20% or so at the cost of a minor regression in JIT speed
- Recognize patterns of common sequences in the JIT backends and optimize them
- Make the garbage collecter more incremental over external_malloc() calls
- Share guard resume data where possible which reduces memory usage
- Fast path for zip(list, list)
- Reduce the number of checks in the JIT for lst[a:]
- Move the non-optimizable part of callbacks outside the JIT
- Factor in field immutability when invalidating heap information
- Unroll itertools.izip_longest() with two sequences
- Minor optimizations after analyzing output from vmprof and trace logs
- Remove many class attributes in rpython classes
- Handle getfield_gc_pure* and getfield_gc_* uniformly in heap.py
- Improve simple trace function performance by lazily calling fast2locals and locals2fast only if truly necessary
Cheers
The PyPy Team
With the SIMD run-time detection implemented, has the --jit-backend option become redundant?
@Gerrit, they are 2 different things. One is the option to say you are interested in the SIMD support and the other is a check if SIMD support is available in the HW if you are interested in using it. I'm sure once SIMD support has been used for some time it will eventually be enabled by default but since it is new and potential could have some unknown issues at this time you have to explicitly enable it at this time.
I keep watching the progress of PyPy with excitement. Cool things happening here. But I continue to be disappointed that it doesn't tip towards Python3. It's dead to me until that becomes the majority effort. :(
The PyPy project contains a large plurality of interests. A lot of the people working on it are volunteers. So PyPy3 will happen if people within the project become interested in that part, or if new people with that interest join the project. At the moment, this seems not happening, which we can all be sad about. However, blaming anybody with differing interest for that situation feels a bit annoying to me.
Well said, I apologize for any whining tone. It was not my intent to blame or complain. It really was just meant as a lamentation. Thanks for all you do.
What happened to my comment? Surely the benchmark I was proposing is not censorable...
@PeteVine you posted a random executable from dropbox claiming to have pypy with x87 backend. PyPy does not have an x87 backend and this raises suspitions this was just some malware. Now if you want someone to compare one thing against some other thing, please link to sources and not random binaries so the person comparing can look themselves. Additionally you did not post a benchmark, just a link to the binary
Well, I was suggesting benchmarking the 32-bit backends to see how much difference SIMD makes - x87 means the standard fpu whereas the default uses SSE2. I know it's processor archaeology so you may have forgotten pypy even had it ;)
The ready-to-use pypy distro (built by me) was meant for anyone in possesion of a real set of benchmarks (not synthetic vector stuff) to be able to try it quickly.
And btw, you could have simply edited the dropbox link out. I'd already tested py3k using this backend and mentioned it in one of the issues on bitbucket so it's far from random.
@ all the people asking about pypy3 - you have the python 3.2 compatible pypy (py3k) at your disposal even now.
@PeteVine: to clarify, PyPy has no JIT backend emitting the old-style x87 fpu instructions. What you are posting is very likely a PyPy whose JIT doesn't support floats at all. It emits calls to already-compiled functions, like the one doing addition of float objects, instead of writing a SSE2 float addition on unboxed objects.
Instead, use the official PyPy and run it with vectorization turned on and off (as documented) on the same modern machine. This allows an apple-to-apple comparison.
Thanks for clarifying, I must have confused myself after seeing it was i486 compatible.
Are you saying the only difference between the backends I wanted to benchmark would boil down to jit-emitting performance and not actual pypy performance? (I must admit I tried this a while ago with fibonacci and there was no difference at all).
In other words, even before vectorization functionality was added, shouldn't it be possible to detect that the non-SSE2 backend is running on newer hardware and use the available SIMD? (e.g. for max. compatibility)
@PeteVine Sorry, I don't understand your questions. Why do you bring the JIT-emitting performance to the table? And why fibonacci (it's not a benchmark with floats at all)? And I don't get the last question either ("SIMD" = "vectorization").
To some people, merely dropping the word "SIMD" into a performance discussion makes them go "ooh nice" even if they don't have a clue what it is. I hope you're more knowledgeable than that and that I'm merely missing your point :-)
The last part should have been pretty clear as it was referring to the newly added –jit vec=1 so it's not me who's dropping SIMD here (shorthand for different instructions sets) as can be seen in the title of this blog post.
All this time I was merely interested in comparing the two 32-bit backends, that's all. One's using the i486/x87 instruction set regardless of any jit codes, the other is able take advantage of anything up to SSE2. The quick fibonacci test was all I did so you could have pointed me to a real set of benchmarks instead of throwing these little jabs :)
@PeteVine: ok, there is a misunderstanding somewhere, I think. Let me try to clarify: PyPy's JIT has always used non-SIMD SSE2 instructions to implement floating point operations. We have a slow mode where only x87 instructions are used, but usually don't fall back to that, and it does not make sense to compare against that mode.
What the new release experimentally added is support for SIMD SSE instructions using autoparallelization when --jit vec=1 is given. This only works if your program uses numpy arrays or other simple list processing code. For details on that (and for benchmarks) it's probably best to read Richard Plangger's blog.
Does that make sense?
Great, love that explanation! :)
But please, I'd really like to see how much of a handicap the much-maligned non-SSE2 backend incurs. Could you recommend a set of python (not purely computational) benchmarks so I can put this peevee of mine to rest/test?
Anyways, @Armin Rigo is a great educator himself judging from his patient replies in the bugtracker! So yeah, kudos to you guys!
If you want to try a proper performance evaluation, the official benchmark set is probably the right one: https://bitbucket.org/pypy/benchmarks/
However, none of these benchmarks are exercising the new autovectorization. If you're particularly interested in that part, use the benchmarks from Richard's blog.
Automatic SIMD vectorization support in PyPy
it took some time to catch up with the JIT refacrtorings merged in this summer. But, (drums) we are happy to announce that:
The next release of PyPy, "PyPy 4.0.0", will ship the new auto vectorizer
The goal of this project was to increase the speed of numerical applications in both the NumPyPy library and for arbitrary Python programs. In PyPy we have focused a lot on improvements in the 'typical python workload', which usually involves object and string manipulations, mostly for web development. We're hoping with this work that we'll continue improving the other very important Python use case - numerics.What it can do!
It targets numerics only. It will not execute object manipulations faster, but it is capable of enhancing common vector and matrix operations.Good news is that it is not specifically targeted for the NumPy library and the PyPy virtual machine. Any interpreter (written in RPython) is able make use of the vectorization. For more information about that take a look here, or consult the documentation. For the time being it is not turn on by default, so be sure to enable it by specifying --jit vec=1 before running your program.
If your language (written in RPython) contains many array/matrix operations, you can easily integrate the optimization by adding the parameter 'vec=1' to the JitDriver.
NumPyPy Improvements
Let's take a look at the core functions of the NumPyPy library (*).The following tests tests show the speedup of the core functions commonly used in Python code interfacing with NumPy, on CPython with NumPy, on the PyPy 2.6.1 relased several weeks ago, and on PyPy 15.11 to be released soon. Timeit was used to test the time needed to run the operation in the plot title on various vector (lower case) and square matrix (upper case) sizes displayed on the X axis. The Y axis shows the speedup compared to CPython 2.7.10. This means that higher is better.

It is a very common operation in numerics and PyPy now (given a moderate sized matrix and vector) decreases the time spent in that operation. See for yourself:
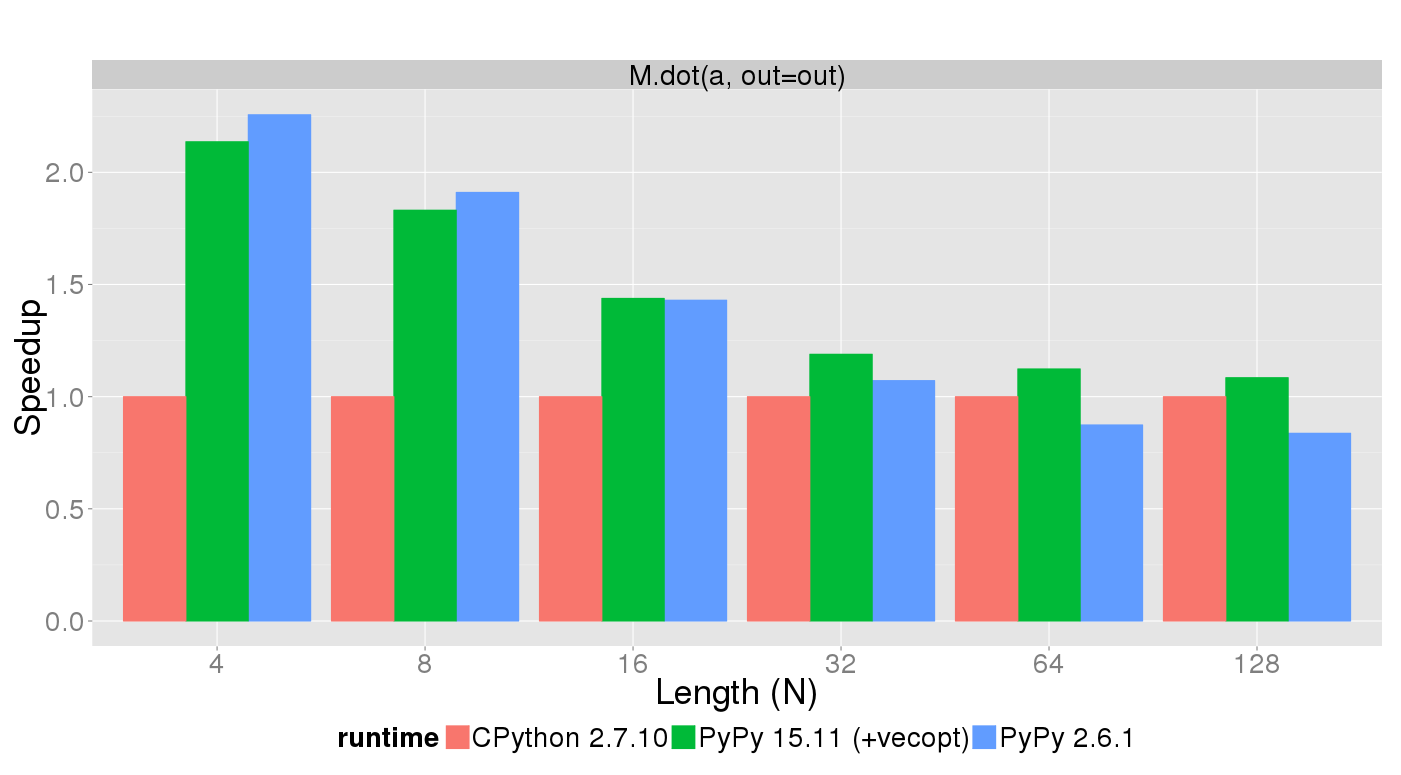
Future work
This is not the end of the road. The GSoC project showed that it is possible to implement this optimization in PyPy. There might be other improvements we can make to carry this further:
- Check alignment at runtime to increase the memory throughput of the CPU
- Support the AVX vector extension which (at least) doubles the size of the vector register
- Handle each and every corner case in Python traces to enable it globally
- Do not rely only on loading operations to trigger the analysis, there might be cases where combination of floating point values could be done in parallel
The PyPy Team
(*) The benchmark code can be found here it was run using this configuration: i7-2600 CPU @ 3.40GHz (4 cores).
How does it compare to numexpr on those benchmarks?
Also, any plan of addressing one of the killer features of numexpr, that is the fact that an operation like y += a1*x1 + a2*x2 + a3*x3 will create 5 temporary vectors and make a horrible usage of the CPU cache?
I don't know anyone who uses NumPy for arrays with less than 128 elements.
Your own benchmark shows NumPypy is much slower than NumPy for large arrays...
NumPyPy is currently not complete. Trying to evaluate any numexpr gives a strange error. I guess the problem is a missing field not exported by NumPyPy.
However we will see how far we can get with this approach. I have made some thoughts on how we could make good use of graphics cards, but this is future work.
PowerPC backend for the JIT
Hi all,
PyPy's JIT now supports the 64-bit PowerPC architecture! This is the third architecture supported, in addition to x86 (32 and 64) and ARM (32-bit only). More precisely, we support Linux running the big- and the little-endian variants of ppc64. Thanks to IBM for funding this work!
The new JIT backend has been merged into "default". You should be able to translate PPC versions as usual directly on the machines. For the foreseeable future, I will compile and distribute binary versions corresponding to the official releases (for Fedora), but of course I'd welcome it if someone else could step in and do it. Also, it is unclear yet if we will run a buildbot.
To check that the result performs well, I logged in a ppc64le machine and ran the usual benchmark suite of PyPy (minus sqlitesynth: sqlite was not installed on that machine). I ran it twice at a difference of 12 hours, as an attempt to reduce risks caused by other users suddenly using the machine. The machine was overall relatively quiet. Of course, this is scientifically not good enough; it is what I could come up with given the limited resources.
Here are the results, where the numbers are speed-up factors between the non-jit and the jit version of PyPy. The first column is x86-64, for reference. The second and third columns are the two ppc64le runs. All are Linux. A few benchmarks are not reported here because the runner doesn't execute them on non-jit (however, apart from sqlitesynth, they all worked).
ai 13.7342 16.1659 14.9091
bm_chameleon 8.5944 8.5858 8.66
bm_dulwich_log 5.1256 5.4368 5.5928
bm_krakatau 5.5201 2.3915 2.3452
bm_mako 8.4802 6.8937 6.9335
bm_mdp 2.0315 1.7162 1.9131
chaos 56.9705 57.2608 56.2374
sphinx
crypto_pyaes 62.505 80.149 79.7801
deltablue 3.3403 5.1199 4.7872
django 28.9829 23.206 23.47
eparse 2.3164 2.6281 2.589
fannkuch 9.1242 15.1768 11.3906
float 13.8145 17.2582 17.2451
genshi_text 16.4608 13.9398 13.7998
genshi_xml 8.2782 8.0879 9.2315
go 6.7458 11.8226 15.4183
hexiom2 24.3612 34.7991 33.4734
html5lib 5.4515 5.5186 5.365
json_bench 28.8774 29.5022 28.8897
meteor-contest 5.1518 5.6567 5.7514
nbody_modified 20.6138 22.5466 21.3992
pidigits 1.0118 1.022 1.0829
pyflate-fast 9.0684 10.0168 10.3119
pypy_interp 3.3977 3.9307 3.8798
raytrace-simple 69.0114 108.8875 127.1518
richards 94.1863 118.1257 102.1906
rietveld 3.2421 3.0126 3.1592
scimark_fft
scimark_lu
scimark_montecarlo
scimark_sor
scimark_sparsematmul
slowspitfire 2.8539 3.3924 3.5541
spambayes 5.0646 6.3446 6.237
spectral-norm 41.9148 42.1831 43.2913
spitfire 3.8788 4.8214 4.701
spitfire_cstringio 7.606 9.1809 9.1691
sqlitesynth
sympy_expand 2.9537 2.0705 1.9299
sympy_integrate 4.3805 4.3467 4.7052
sympy_str 1.5431 1.6248 1.5825
sympy_sum 6.2519 6.096 5.6643
telco 61.2416 54.7187 55.1705
trans2_annotate
trans2_rtype
trans2_backendopt
trans2_database
trans2_source
twisted_iteration 55.5019 51.5127 63.0592
twisted_names 8.2262 9.0062 10.306
twisted_pb 12.1134 13.644 12.1177
twisted_tcp 4.9778 1.934 5.4931
GEOMETRIC MEAN 9.31 9.70 10.01
The last line reports the geometric mean of each column. We see that the goal was reached: PyPy's JIT actually improves performance by a factor of around 9.7 to 10 times on ppc64le. By comparison, it "only" improves performance by a factor 9.3 on Intel x86-64. I don't know why, but I'd guess it mostly means that a non-jitted PyPy performs slightly better on Intel than it does on PowerPC.
Why is that? Actually, if we do the same comparison with an ARM column too, we also get higher numbers there than on Intel. When we discovered that a few years ago, we guessed that on ARM running the whole interpreter in PyPy takes up a lot of resources, e.g. of instruction cache, which the JIT's assembler doesn't need any more after the process is warmed up. And caches are much bigger on Intel. However, PowerPC is much closer to Intel, so this argument doesn't work for PowerPC. But there are other more subtle variants of it. Notably, Intel is doing crazy things about branch prediction, which likely helps a big interpreter---both the non-JITted PyPy and CPython, and both for the interpreter's main loop itself and for the numerous indirect branches that depend on the types of the objects. Maybe the PowerPC is as good as Intel, and so this argument doesn't work either. Another one would be: on PowerPC I did notice that gcc itself is not perfect at optimization. During development of this backend, I often looked at assembler produced by gcc, and there are a number of small inefficiencies there. All these are factors that slow down the non-JITted version of PyPy, but don't influence the speed of the assembler produced just-in-time.
Anyway, this is just guessing. The fact remains that PyPy can now be used on PowerPC machines. Have fun!
A bientôt,
Armin.
PyPy memory and warmup improvements (2) - Sharing of Guards
Hello everyone!
This is the second part of the series of improvements in warmup time and memory consumption in the PyPy JIT. This post covers recent work on sharing guard resume data that was recently merged to trunk. It will be a part of the next official PyPy release. To understand what it does, let's start with a loop for a simple example:
class A(object):
def __init__(self, x, y):
self.x = x
self.y = y
def call_method(self, z):
return self.x + self.y + z
def f():
s = 0
for i in range(100000):
a = A(i, 1 + i)
s += a.call_method(i)
At the entrance of the loop, we have the following set of operations:
guard(i5 == 4)guard(p3 is null)p27 = p2.co_cellvars p28 = p2.co_freevarsguard_class(p17, 4316866008, descr=<Guard0x104295e08>)p30 = p17.w_seqguard_nonnull(p30, descr=<Guard0x104295db0>)i31 = p17.index p32 = p30.strategyguard_class(p32, 4317041344, descr=<Guard0x104295d58>)p34 = p30.lstorage i35 = p34..item0
The above operations gets executed at the entrance, so each time we call f(). They ensure all the optimizations done below stay valid. Now, as long as nothing out of the ordinary happens, they only ensure that the world around us never changed. However, if e.g. someone puts new methods on class A, any of the above guards might fail. Despite the fact that it's a very unlikely case, PyPy needs to track how to recover from such a situation. Each of those points needs to keep the full state of the optimizations performed, so we can safely deoptimize them and reenter the interpreter. This is vastly wasteful since most of those guards never fail, hence some sharing between guards has been performed.
We went a step further - when two guards are next to each other or the operations in between them don't have side effects, we can safely redo the operations or to simply put, resume in the previous guard. That means every now and again we execute a few operations extra, but not storing extra info saves quite a bit of time and memory. This is similar to the approach that LuaJIT takes, which is called sparse snapshots.
I've done some measurements on annotating & rtyping translation of pypy, which is a pretty memory hungry program that compiles a fair bit. I measured, respectively:
- total time the translation step took (annotating or rtyping)
- time it took for tracing (that excludes backend time for the total JIT time) at the end of rtyping.
- memory the GC feels responsible for after the step. The real amount of memory consumed will always be larger and the coefficient of savings is in 1.5-2x mark
Here is the table:
| branch | time annotation | time rtyping | memory annotation | memory rtyping | tracing time |
|---|---|---|---|---|---|
| default | 317s | 454s | 707M | 1349M | 60s |
| sharing | 302s | 430s | 595M | 1070M | 51s |
| win | 4.8% | 5.5% | 19% | 26% | 17% |
Obviously pypy translation is an extreme example - the vast majority of the code out there does not have that many lines of code to be jitted. However, it's at the very least a good win for us :-)
We will continue to improve the warmup performance and keep you posted!
Cheers,
fijal
"when two guards are next to each other or the operations in between them don't have side effects, we can safely redo the operations or to simply put, resume in the previous guard"
Wait... "side effects", "redo"... Does this have synergies with STM?
Side effect operation is one that does not have any side effects. This means that you can execute the operation again (e.g. reading a field or adding two numbers) and will affect nothing but it's result. As for redo - well, it has nothing to do with STM, but doing pure operations again can be sometimes useful (in short - if you have i = a + b, you don't remember the i, just a, b and that i = a + b)
PyPy warmup improvements
Hello everyone!
I'm very pleased to announce that we've just managed to merge the optresult branch. Under this cryptic name is the biggest JIT refactoring we've done in a couple years, mostly focused on the warmup time and memory impact of PyPy.
To understand why we did that, let's look back in time - back when we got the first working JIT prototype in 2009 we were focused exclusively on achieving peak performance with some consideration towards memory usage, but without serious consideration towards warmup time. This means we accumulated quite a bit of technical debt over time that we're trying, with difficulty, to address right now. This branch mostly does not affect the peak performance - it should however help you with short-living scripts, like test runs.
We identified warmup time to be one of the major pain points for pypy users, along with memory impact and compatibility issues with CPython C extension world. While we can't address all the issues at once, we're trying to address the first two in the work contributing to this blog post. I will write a separate article on the last item separately.
To see how much of a problem warmup is for your program, you can run your program with PYPYLOG=jit-summary:- environment variable set. This should show you something like this:
(pypy-optresult)fijal@hermann:~/src/botbot-web$ PYPYLOG=jit-summary:- python orm.py 1500
[d195a2fcecc] {jit-summary
Tracing: 781 2.924965
Backend: 737 0.722710
TOTAL: 35.912011
ops: 1860596
recorded ops: 493138
calls: 81022
guards: 131238
opt ops: 137263
opt guards: 35166
forcings: 4196
abort: trace too long: 22
abort: compiling: 0
abort: vable escape: 22
abort: bad loop: 0
abort: force quasi-immut: 0
nvirtuals: 183672
nvholes: 25797
nvreused: 116131
Total # of loops: 193
Total # of bridges: 575
Freed # of loops: 6
Freed # of bridges: 75
[d195a48de18] jit-summary}
This means that the total (wall clock) time was 35.9s, out of which we spent 2.9s tracing 781 loops and 0.72s compiling them. The remaining couple were aborted (trace too long is normal, vable escape means someone called sys._getframe() or equivalent). You can do the following things:
- compare the numbers with pypy --jit off and see at which number of iterations pypy jit kicks in
- play with the thresholds: pypy --jit threshold=500,function_threshold=400,trace_eagerness=50 was much better in this example. What this does is to lower the threshold for tracing loops from default of 1039 to 400, threshold for tracing functions from the start from 1619 to 500 and threshold for tracing bridges from 200 to 50. Bridges are "alternative paths" that JIT did not take that are being additionally traced. We believe in sane defaults, so we'll try to improve upon those numbers, but generally speaking there is no one-size fits all here.
- if the tracing/backend time stays high, come and complain to us with benchmarks, we'll try to look at them
Warmup, as a number, is notoriously hard to measure. It's a combination of:
- pypy running interpreter before jitting
- pypy needing time to JIT the traces
- additional memory allocations needed during tracing to accomodate bookkeeping data
- exiting and entering assembler until there is enough coverage of assembler
We're working hard on making a better assesment at this number, stay tuned :-)
Speedups
Overall we measured about 50% speed improvement in the optimizer, which reduces the overall warmup time between 10% and 30%. The very obvious warmup benchmark got a speedup from 4.5s to 3.5s, almost 30% improvement. Obviously the speedups on benchmarks would vastly depend on how much warmup time is there in those benchmarks. We observed annotation of pypy to decreasing by about 30% and the overall translation time by about 7%, so your mileage may vary.
Of course, as usual with the large refactoring of a crucial piece of PyPy, there are expected to be bugs. We are going to wait for the default branch to stabilize so you should see warmup improvements in the next release. If you're not afraid to try, nightlies will already have them.
We're hoping to continue improving upon warmup time and memory impact in the future, stay tuned for improvements.
Technical details
The branch does "one" thing - it changes the underlying model of how operations are represented during tracing and optimizations. Let's consider a simple loop like:
[i0, i1] i2 = int_add(i0, i1) i3 = int_add(i2, 1) i4 = int_is_true(i3) guard_true(i4) jump(i3, i2)
The original representation would allocate a Box for each of i0 - i4 and then store those boxes in instances of ResOperation. The list of such operations would then go to the optimizer. Those lists are big - we usually remove 90% of them during optimizations, but they can be a couple thousand elements. Overall, allocating those big lists takes a toll on warmup time, especially due to the GC pressure. The branch removes the existance of Box completely, instead using a link to ResOperation itself. So say in the above example, i2 would refer to its producer - i2 = int_add(i0, i1) with arguments getting special treatment.
That alone reduces the GC pressure slightly, but a reduced number of instances also lets us store references on them directly instead of going through expensive dictionaries, which were used to store optimizing information about the boxes.
Cheers!
fijal & arigo
PyPy 2.6.1 released
PyPy 2.6.1
We’re pleased to announce PyPy 2.6.1, an update to PyPy 2.6.0 released June 1. We have fixed many issues, updated stdlib to 2.7.10, cffi to version 1.3, extended support for the new vmprof statistical profiler for multiple threads, and increased functionality of numpy.You can download the PyPy 2.6.1 release here:
We would like to thank our donors for the continued support of the PyPy project, and our volunteers and contributors.
We would also like to encourage new people to join the project. PyPy has many layers and we need help with all of them: PyPy and RPython documentation improvements, tweaking popular modules to run on pypy, or general help with making RPython’s JIT even better.
What is PyPy?
PyPy is a very compliant Python interpreter, almost a drop-in replacement for CPython 2.7. It’s fast (pypy and cpython 2.7.x performance comparison) due to its integrated tracing JIT compiler.This release supports x86 machines on most common operating systems (Linux 32/64, Mac OS X 64, Windows 32, OpenBSD, freebsd), as well as newer ARM hardware (ARMv6 or ARMv7, with VFPv3) running Linux.
We also welcome developers of other dynamic languages to see what RPython can do for them.
Highlights
- Bug Fixes
- Revive non-SSE2 support
- Fixes for detaching _io.Buffer*
- On Windows, close (and flush) all open sockets on exiting
- Drop support for ancient macOS v10.4 and before
- Clear up contention in the garbage collector between trace-me-later and pinning
- Issues reported with our previous release were resolved after reports from users on our issue tracker at https://foss.heptapod.net/pypy/pypy/-/issues or on IRC at #pypy.
- New features:
- cffi was updated to version 1.3
- The python stdlib was updated to 2.7.10 from 2.7.9
- vmprof now supports multiple threads and OS X
- The translation process builds cffi import libraries for some stdlib packages, which should prevent confusion when package.py is not used
- better support for gdb debugging
- freebsd should be able to translate PyPy “out of the box” with no patches
- Numpy:
- Better support for record dtypes, including the
alignkeyword - Implement casting and create output arrays accordingly (still missing some corner cases)
- Support creation of unicode ndarrays
- Better support ndarray.flags
- Support
axisargument in more functions - Refactor array indexing to support ellipses
- Allow the docstrings of built-in numpy objects to be set at run-time
- Support the
bufferednditer creation keyword
- Better support for record dtypes, including the
- Performance improvements:
- Delay recursive calls to make them non-recursive
- Skip loop unrolling if it compiles too much code
- Tweak the heapcache
- Add a list strategy for lists that store both floats and 32-bit integers. The latter are encoded as nonstandard NaNs. Benchmarks show that the speed of such lists is now very close to the speed of purely-int or purely-float lists.
- Simplify implementation of ffi.gc() to avoid most weakrefs
- Massively improve the performance of map() with more than one sequence argument
Cheers
The PyPy Team
Cool! Really nice, thank you. Any ETA for Python 3.3 compatibility in pypy?
Still waiting for PyPy3's update. The latest version of PyPy is much faster than the latest version of PyPy3. Please update soon. :)
Contrary to what the front page is still saying, the non-SSE2 backend for older x86 processors is fully working and can be built from source, which takes almost 7h on a 2.2GHz Athlon XP.
You can download a 2.6.1 build from here:
https://www.dropbox.com/sh/6i7ktwv9551asfc/AADOd55Br0lDJRH8HsKpbIwTa?dl=0
It should work on any P2 class processor.
PyPy and ijson - a guest blog post
"So, I was playing around with parsing huge JSON files (19GiB, testfile is ~520MiB) and wanted to try a sample code with PyPy, turns out, PyPy needed ~1:30-2:00 whereas CPython 2.7 needed ~13 seconds (the pure python implementation on both pythons was equivalent at ~8 minutes).
"Apparantly ctypes is really bad performance-wise, especially on PyPy. So I made a quick CFFI mockup: https://gist.github.com/Dav1dde/c509d472085f9374fc1d
Before:
CPython 2.7:
python -m emfas.server size dumps/echoprint-dump-1.json
11.89s user 0.36s system 98% cpu 12.390 total
PYPY:
python -m emfas.server size dumps/echoprint-dump-1.json
117.19s user 2.36s system 99% cpu 1:59.95 total
After (CFFI):
CPython 2.7:
python jsonsize.py ../dumps/echoprint-dump-1.json
8.63s user 0.28s system 99% cpu 8.945 total
PyPy:
python jsonsize.py ../dumps/echoprint-dump-1.json
4.04s user 0.34s system 99% cpu 4.392 total
"
Dav1dd goes into more detail in the issue itself, but we just want to emphasize a few significant points from this brief interchange:
- His CFFI implementation is faster than the ctypes one even on CPython 2.7.
- PyPy + CFFI is faster than CPython even when using C code to do the heavy parsing.
Maybe it's time to discuss inclusion of CFFI into stdandard library again?
If CPython decides to include it in its stdlib, I can make sure it is updated as needed. I don't have the energy to discuss its inclusion myself, so if it happens it will be "championed" by someone else. Nowadays, I personally think inclusion has as many drawbacks as advantages, even if CFFI 1.x shouldn't evolve a lot in the foreseeable future after the 1.0 step.
The problem is converting existing libs to use cffi. Only very few percent of Libs are ready for python3.x and with this trend , not even 1% of libs will be converted to work with CFFI.
That makes PyPy adoption a lot slower.
Is there really no chance of improving ctypes?
Thanks to apollo13 on irc for early feedback. Main change: the code put in embedded_init_code() should now start with "from xx import ffi", where "xx" is the name of the module (first argument to set_source()). The goal is to clearly say that you need the same line in other modules imported from there.
This is very exciting! Just waiting for Python 3.x support now. :)
Python 3 is implemented and tested now.
Windows support is now done (tested on Python 2.7). Expect a release soon :-)
Excelent feature!!
CFFI rocks, and the documentation keeps improving :)
Awesome, pypyInstaller in cross-hairs!